I started a new painting on the chapter “Burning and Unburning” by Elizabeth A. R. Brown in the book People in Groups, edited by Richard Trexler (1985).

If you had a group of three dinosaurs, how would you call them?
Art | Knowledge Mobilization | Multiform Grammar
I started a new painting on the chapter “Burning and Unburning” by Elizabeth A. R. Brown in the book People in Groups, edited by Richard Trexler (1985).
If you had a group of three dinosaurs, how would you call them?

I gave a class today in my online Digital History course on the connection between neuroscience, AI, and history. My initial plan was to deliver it as the last class on Apr 10, to summarize the course while raising questions about the future of historical research considering the rise of AI. I also wanted to ponder how researchers in history can utilize interdisciplinary approaches such as this biological-technological one. However, both the timing of the class and its discussion took their own direction.
Due to logistical reasons, the class took place earlier; that’s fine. The discussion, however, surprised me, and I’m now wondering why what seems fascinating and important to me didn’t get students’ focus and attention. We started with watching the excellent documentary Toward Singularity, directed by Matthew Dahlitz (2020, 1:05 hrs). In it, Dahlitz combines experts’ insights into brain studies and the development of AI, as well as the experts’ vision of the latter in the near and far future. One example is Dr. Nicole Robinson’s work on integrating robots into human society and environment, to achieve a symbiotic relationship between them and people. Another example is Dr. David Howard’s work on making robots a species that has the capacity to change over time through Darwinian evolution.
I planned to think with the students about history: How will it look in the future? Would robots or intelligent machines write “our” (whatever it means) history? In fact, with the current GPT technologies, it’s already taking place. Further, can historians utilize this bio-tech approach to advance their historical knowledge? Would super-intelligent machines correct our misconceptions of history? Or perhaps misrepresent it altogether? To make these issues the core of the discussion, I went over two slides before we watched the film. The first shows the chapters in the film, which indicate how the director defined the main questions and arranged them in order (Fig. 1). As I regularly upload the slides to the course website, this list will also enable the students to re-watch the chapters that interest them most.

The second slide shows the concepts the experts in the film explain, which I supposed will shape the discussion as I planned (Fig. 2). I knew that when the students watch the film, they will already have those concepts in their minds and hoped that it’d make it easier for us to discuss the future of human history and historiography. Nevertheless, after watching the film, a significant part of the discussion focused on aspects that characterize humans as service givers, which – so it was assumed – are impossible to imitate. Interestingly, it was in response to Dr. Peter Bishop’s argument that the existing process of deskilling society with machines in workplaces will only increase as machines become more intelligent. The result of this development, he says, is the deskilling of the professional, educated class. This argument triggered the students who found the description of the “unskilled” class elitist and unrealistic as it ignores the additional “human qualities” they bring into their roles, which cannot be replaced by machines. Although I planned to talk about the future of historical research considering current developments, we had dived into class tensions; those between theoreticians and the working class, and those between humans and machines.
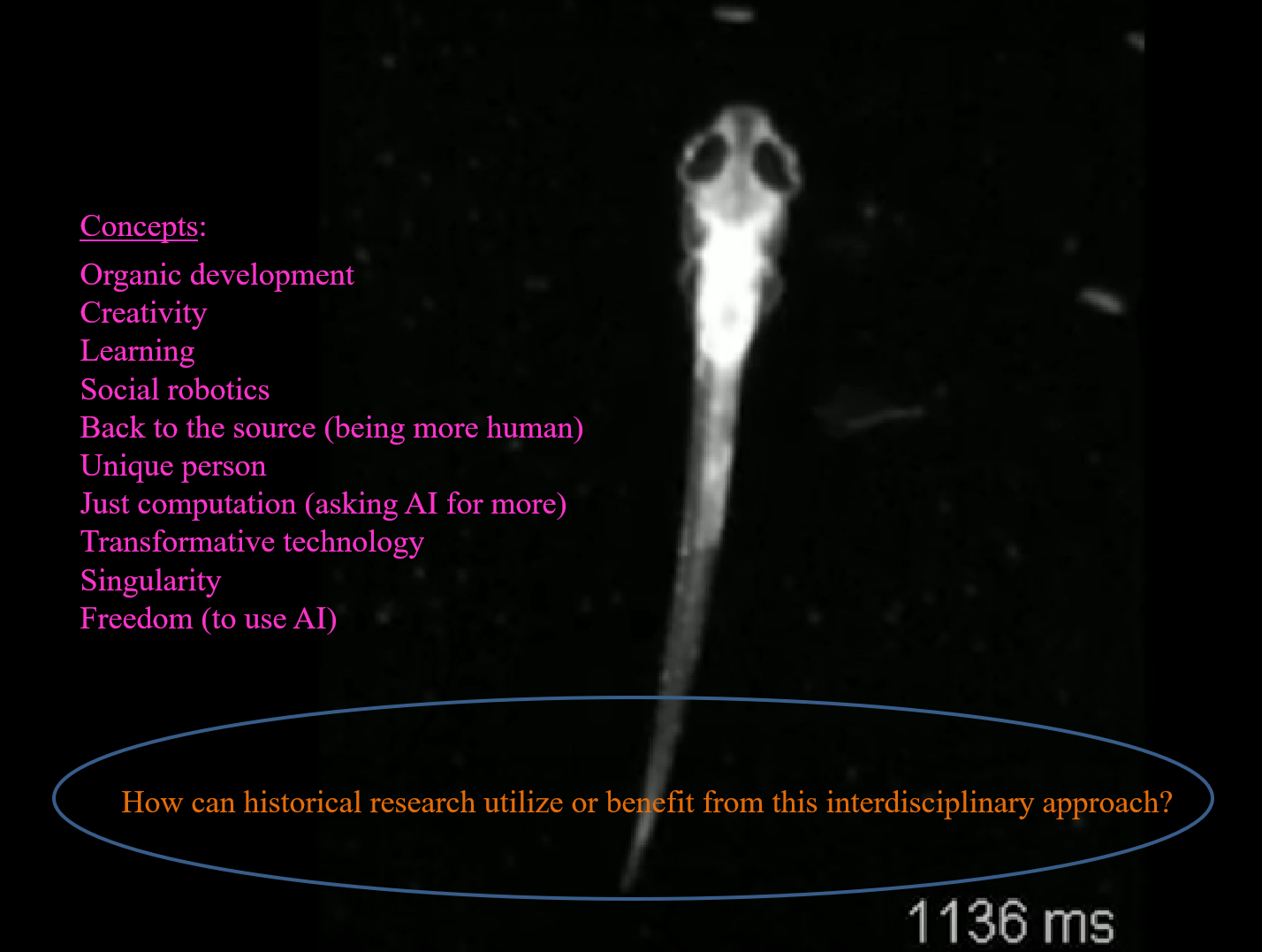 Fig. 2 Digital History – slide with concepts from Toward Singularity and a question
Fig. 2 Digital History – slide with concepts from Toward Singularity and a questionWhat can we learn from this situation? I think that the students gravitated to what is most relevant to their present: finding their place in the world as they develop their skill set and before they have a clear professional identity. This journey is challenging even when AI, social robots, and super-intelligent algorithms are not part of the game. In the documentary, Dr. Ronald Arkin claims that the “robotics revolution” poses threat to employment, but that new jobs will be created as well. According to him, it’s necessary for society to provide a safety net as we move through it. However, he adds, “one could argue that no job is safe, even that of a professor.”
 I recently gave my students, in the course Digital History (U of T), an online quiz that includes ten multiple-choice questions. One of the questions is about a video game titled Tag Attack, which was submitted by Antonio to the British Library Labs Crowdsourcing Game Jam. This project took place in 2015 utilizing gaming and crowdsourcing to add information to the 19th-century image collection of the British Library.
I recently gave my students, in the course Digital History (U of T), an online quiz that includes ten multiple-choice questions. One of the questions is about a video game titled Tag Attack, which was submitted by Antonio to the British Library Labs Crowdsourcing Game Jam. This project took place in 2015 utilizing gaming and crowdsourcing to add information to the 19th-century image collection of the British Library.
In Tag Attack, a fox moves from the right to the left side of the screen carrying an image from the library’s collection. The player’s task is to classify the image into one of four given categories before the fox gets to the edge of the screen. The fox’s speed challenges the player to tag the images quickly; this, in turn, excites the player and ensures efficient classification of the images for the library. It’s not clear, however, how the library ensures that the classification is correct. To do so, they need to have the information they seek to gain through the games.
I became familiar with the project through watching an interview with Adam Crymble, who initiated it and is currently a professor of Digital Humanities at University College London. The project, according to Crymble, intends to distribute such games in public spaces on 1980‘s style arcade machines attempting to engage people through physical objects rather than websites. He argues that the fact that websites are available for everybody reduces the chances that people will look for a specific website. On the other hand, “stumbling across” an interactive object like an arcade machine in public places, may better attract individuals to engage with the game.
The multiple-choice question in the quiz asks the students to select an answer that describes the task in Tag Attack accurately. By doing so, it resembles the task in the game as both challenging the participants with the need to decide about an image in a limited time. In the quiz, however, the right answer is known before the students take the quiz. Interestingly, the rate of success in answering this question was the lowest among all ten questions, indicating that only slightly more than half of the students knew the right answer.
In my opinion, this question is not more complex or challenging than any other question in the quiz, therefore, the low rate of answering it correctly, requires thinking. First, it was the only visual question in the quiz. All the other questions were articulated verbally, focusing on insights and concepts from three texts we read and from the interview with Crymble. Perhaps, the use of visual material in a multi-choice assessment is not common and thus required the students to approach the question confidently without having substantive experience with this kind of question.
Second, 24% of the students chose the fourth answer suggesting that the players in the game have to make their decision before “The fox disappears with the image.” This possible answer doesn’t make sense to me. In fact, I regarded it as one of the answers, I included in the quiz, which deliberately makes no sense. Considering a rationale of a game, an action within a timeframe (until the fox disappears) without a spatial scope (the space the fox acts in), makes the elements in the game arbitrary and thus meaningless. Moreover, since the game’s objective is to yield useful information about the images from the players for the library, there is an obvious interest to build a game that is easy to understand, rewarding, and enjoyable.
Why did 15 students choose the disappearance of the fox as the moment until which the players have to tag the image? Why did that disappearance make more sense to them than the right answer or the other two? I’m wondering whether the students subconsciously held an image of the quiz “disappearing” before they managed to answer the question. As mentioned above, the question resembles the game as it asks the participants to choose one out of four alternatives in a limited time. The similarity between the content of the question, on the one hand, and its structure and conditions, on the other, suggests that formalistic aspects influence students’ ability to succeed. If so, we should consider these aspects as part of the content.
During the academic winter break, I’ve been developing the course Digital History, which takes place in the upcoming term at the Department of History at the University of Toronto. Mostly, I prepared the syllabus, which includes the description and structure of the course, learning outcomes, assignments, marking scheme, assigned readings, schedule of guest talks, as well as additional sources, expectations, and policies.
The preparation of the syllabus was an opportunity to practice the use of visuals in a formal document that needs to be clear, precise, and welcoming. The syllabus, with the course website and the presentations in the lectures, will function as one pedagogical, aesthetic body, which will create a style for the course. I’m planning to utilize colours and icons to connect these three-course components. Repetition of visual cues will help the students identify the conceptual continuity between the course materials and, in turn, the overall coherence of the course.
Adding visuals to the syllabus has further functions. For example, colours make the document surprising and cheerful and thus improve the readers’ mood. As well, the choice of colours and icons can sustain the attention of the readers, who might ask questions about the design of the syllabus beyond its role as a guide to the course. Since the students will work on a creative project in the course, their thoughts about design will be relevant and useful.
The visuals in the syllabus encourage an experimental approach to work. The syllabus doesn’t look like many other syllabi, although I examined several of them carefully and applied principles, I found helpful (including the use of visuals). But the look of the syllabus makes it unique and encourages the students to confidently develop their own design preferences and singularity.
Lastly, there are benefits in explaining ideas through various kinds of communication. Considering the diversity in today’s classes, the probability that some of the students will find the visuals more relatable is high. That relatability would make it easier for them to understand and remember their new environment better and, ultimately, become active and contributive players in it.
The “Netiquette” section of the syllabus is pasted below. Happy new year!


The opening reception of my art project “Artist in Residence” took place on Thursday, Oct 20, at the Centre for Jewish Studies, York University. In it, I gave everyone a signed magnet as a gift.
Currently, I have more than 300 magnets to give!
Date: Thursday, October 20, 2022
Time: 4 pm
In-person: The Centre for Jewish Studies, 7th floor of the Kaneff Tower on the Keele campus, York University
“Artist in Residence” is an art project Yaari created at home for the Centre for Jewish Studies when the campus was closed due to the COVID-19 pandemic. It is a series of twenty colourful paintings telling a personal and communal story about fear, faith, isolation, and love. At the opening reception, we will be celebrating this project and the contribution of the arts to our community and to the social and intellectual life on campus.

Dr. Noa Yaari is an artist and art-based knowledge broker. In her work, she explores combinations of words and images in academic, artistic, and daily practices. She holds a PhD in History and MA in Humanities from York University, and an MA in History and Philosophy of Science and Ideas (magna cum laude) from Tel Aviv University. In addition to her solo exhibition at the CJS, she is currently working on an art installation at the Centre for Renaissance and Reformation Studies at the University of Toronto, in which she is a Fellow. Both projects practice art-based knowledge mobilization as well as community building and placemaking on campus.
To RSVP, if you are subscribed to our list serve, please click below. Otherwise, please email cjs@yorku.ca and confirm your attendance in the subject line.
We thank the Alumni Engagement Team, Division of Advancement, and the Faculty of Graduate Studies for their support.
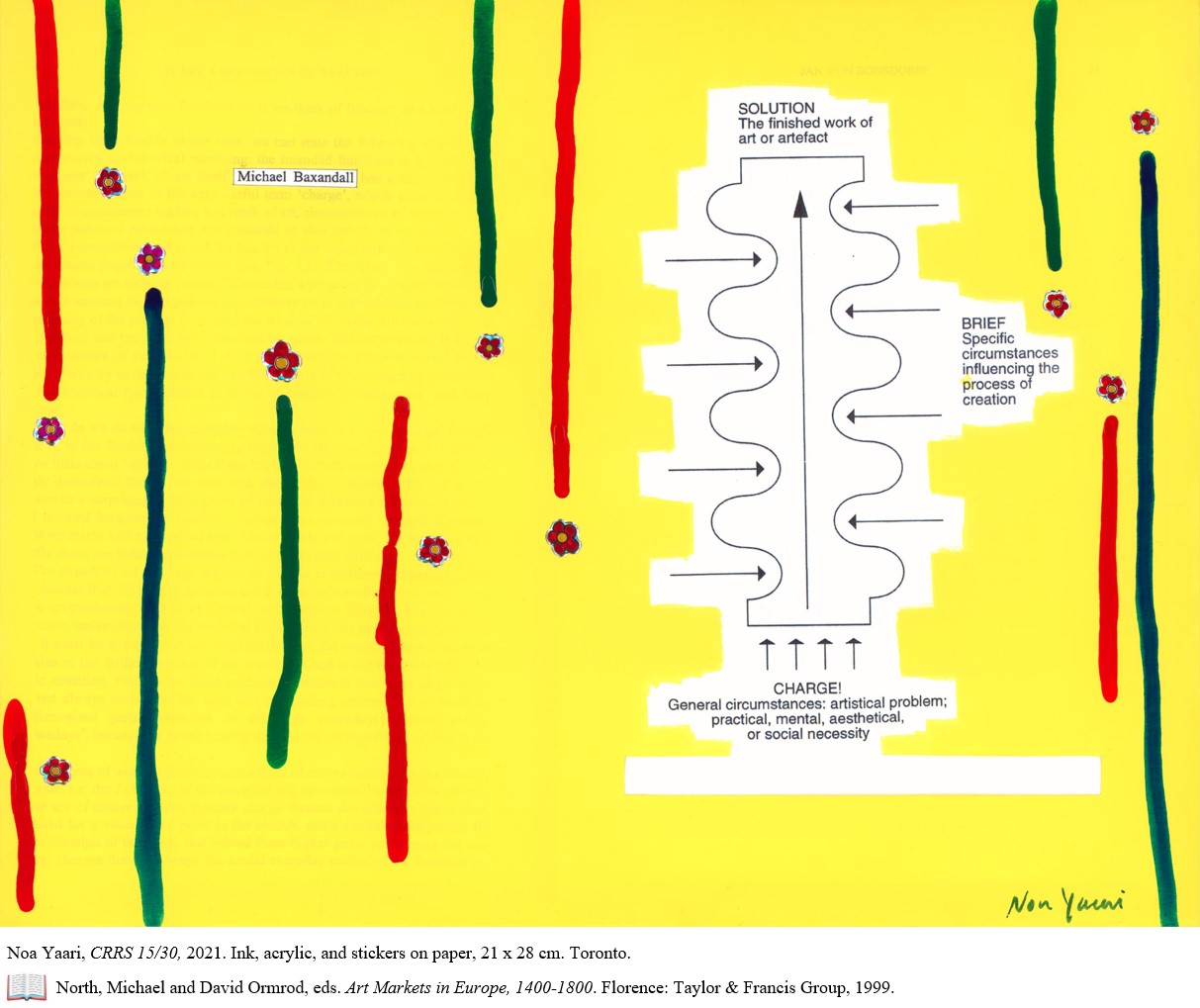
Art historian Michael Baxandall suggested seeing art as a solution to a problem, where necessities of different kinds “charge” the urge to create it. Accordingly, he saw art historians’ role as giving an account of the factors which brought forth and shaped the finished artwork.
I painted on pages 30-31 in Jan von Bonsdorff’s article “Is Art a Barometer of Wealth? Medieval Art Exports to the Far North of Europe,” where he pointed out the problem of conducting historical research without sources outside of the artwork and visualized Baxandall’s model.
Following Von Bonsdorff’s point, I’m wondering what art historians can do when the situation is the opposite; plenty of factors and sources relevant to the artwork but hard to grasp and describe.

Several weeks ago, I started the process of adopting a child through the Public Adoption in Ontario. I’m also reading Chicken Soup for the Soul by Jack Canfield and Mark Victor Hansen (1993) these days. In it, they print Kahlil Gibran’s On Children from the book The Prophet (1923), but they titled it On Parenting. At any rate, I’m bringing it here because it’s beautiful and inspiring.
Your children are not your children. They are the sons and daughters of Life’s longing for itself. They come through you but not from you, And though they are with you yet they belong not to you. You may give them your love but not your thoughts, For they have their own thoughts. You may house their bodies but not their souls, For their souls dwell in the house of tomorrow, which you cannot visit, not even in your dreams. You may strive to be like them, but seek not to make them like you. For life goes not backward nor tarries with yesterday. You are the bows from which your children as living arrows are sent forth. The archer sees the mark upon the path of the infinite, and He bends you with His might that His arrows may go swift and far. Let your bending in the Archer’s hand be for gladness; For even as he loves the arrow that flies, so He loves also the bow that is stable.

In Think and Grow Rich, Napoleon Hill writes “The man who has been active on campus, whose personality is such that he gets along with all kinds of people and who has done an adequate job with his studies has a most decided edge over the strictly academic student. Some of these, because of their all-rounded qualifications, have received several offers of positions […]” (1960, p. 60).
But an emojis is not a “man.” So, what is the advantage of being an all-rounded emoji? And what is an “all-rounded emoji” anyway?
An all-rounded emoji is an emoji that has more than one image in the system: a close-up and a whole-body one. Having these two kinds of representations reveals more about the emoji. The close-up shows its facial expression and mood; for example, whether it’s happy or about to say something. An image of the whole body shows its body language and attitude; for instance, if it’s playful or grounded.
An emoji can present its all-roundedness through some complexity between its facial expression and body language. If we look at the pig and the rabbit above, we can see that their facial expression and body language signify different moods, where the faces are more energetic than the bodies. The cat and the dog seem to have the same cheerful state of mind in both their images. Like the pig and the rabbit, the monkey seems to hold varied dispositions. Most noticeable is its ability to turn its body and head in different directions; a posture that cannot be maintained for a long time, and thus, indicates dynamic attention.
So, what is the advantage of being an all-rounded emoji? If the emoji’s interest is to be used as many times as possible, then obviously, having several different images of it increases the times that it is used. In other words, its multi-faceted personality can match different types of moods and can get “along with all kinds of people.”

